RStudio AI Blog

torch outside the box
Sometimes, a software's best feature is the one you've added yourself. This post shows, by example, why you may want to extend torch, and how to proceed. It also explains a bit of what is going on in the background.

Pre-processing layers in keras: What they are and how to use them
For keras, the last two releases have brought important new functionality, in terms of both low-level infrastructure and workflow enhancements. This post focuses on an outstanding example of the latter category: a new family of layers designed to help with pre-processing, data-augmentation, and feature-engineering tasks.

Keras for R is back!
For a while, it may have seemed that Keras for R was in some undecidable state, like Schrödinger's cat before inspection. It is high time to correct that impression. Keras for R is back, with two recent releases adding powerful capabilities that considerably lighten previously tedious tasks. This post provides a high-level overview. Future posts will go into more detail on some of the most helpful new features, as well as dive into the powerful low-level enhancements that make the former possible.
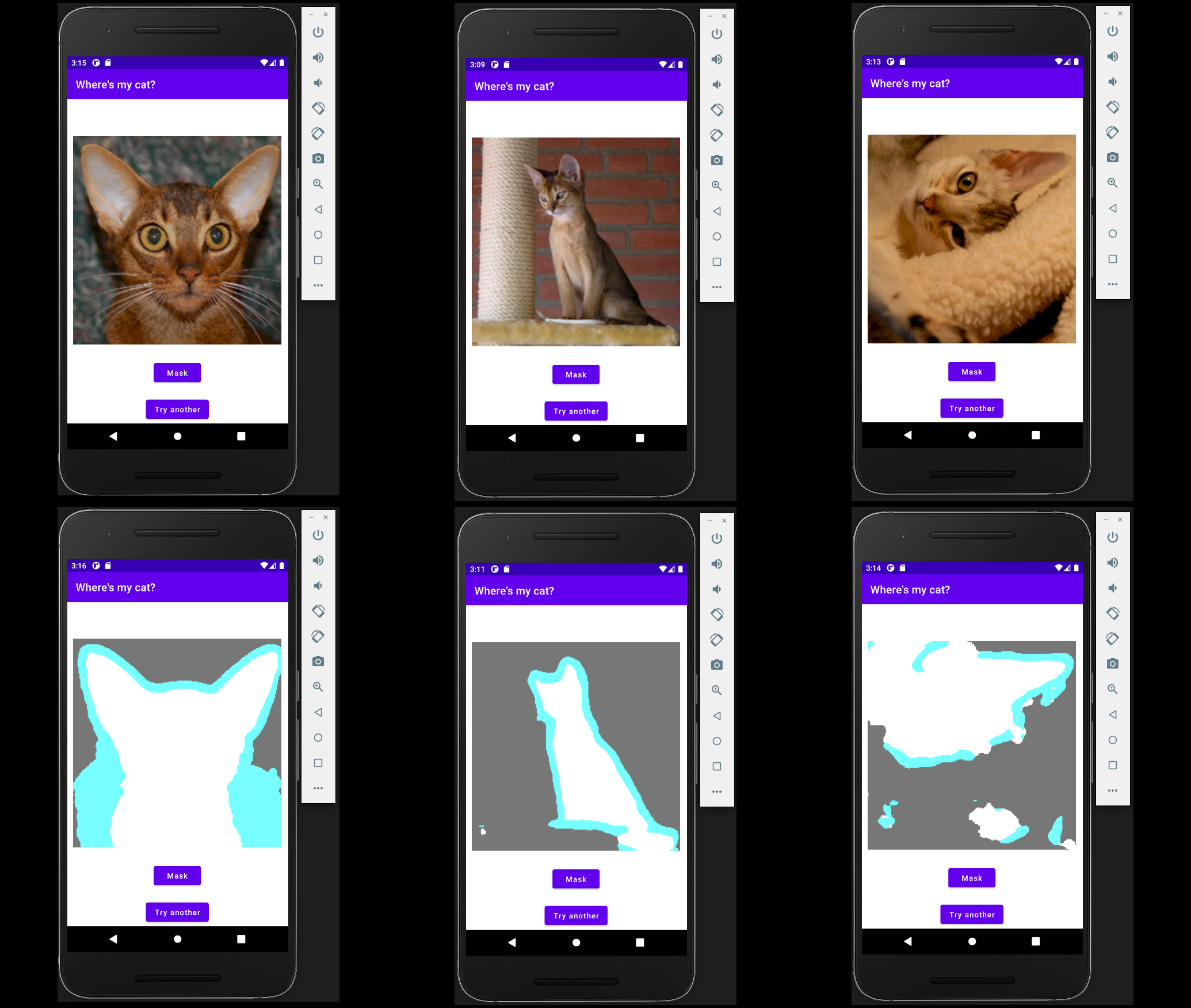
Train in R, run on Android: Image segmentation with torch
We train a model for image segmentation in R, using torch together with luz, its high-level interface. We then JIT-trace the model on example input, so as to obtain an optimized representation that can run with no R installed. Finally, we show the model being run on Android.

Beyond alchemy: A first look at geometric deep learning
Geometric deep learning is a "program" that aspires to situate deep learning architectures and techniques in a framework of mathematical priors. The priors, such as various types of invariance, first arise in some physical domain. A neural network that well matches the domain will preserve as many invariances as possible. In this post, we present a very conceptual, high-level overview, and highlight a few applications.

torch: Just-in-time compilation (JIT) for R-less model deployment
Using the torch just-in-time (JIT) compiler, it is possible to query a model trained in R from a different language, provided that language can make use of the low-level libtorch library. This post shows how. In addition, we try to untangle a bit of the terminological jumble surrounding the topic.

Starting to think about AI Fairness
The topic of AI fairness metrics is as important to society as it is confusing. Confusing it is due to a number of reasons: terminological proliferation, abundance of formulae, and last not least the impression that everyone else seems to know what they're talking about. This text hopes to counteract some of that confusion by starting from a common-sense approach of contrasting two basic positions: On the one hand, the assumption that dataset features may be taken as reflecting the underlying concepts ML practitioners are interested in; on the other, that there inevitably is a gap between concept and measurement, a gap that may be bigger or smaller depending on what is being measured. In contrasting these fundamental views, we bring together concepts from ML, legal science, and political philosophy.

sparklyr.sedona: A sparklyr extension for analyzing geospatial data
We are excited to announce the availability of sparklyr.sedona, a sparklyr extension making geospatial functionalities of the Apache Sedona library easily accessible from R.

sparklyr 1.7: New data sources and spark_apply() capabilities, better interfaces for sparklyr extensions, and more!
Sparklyr 1.7 delivers much-anticipated improvements, including R interfaces for image and binary data sources, several new spark_apply() capabilities, and better integration with sparklyr extensions.

Que haja luz: More light for torch!
Today, we're introducing luz, a high-level interface to torch that lets you train neural networks in a concise, declarative style. In some sense, it is to torch what Keras is to TensorFlow: It provides both a streamlined workflow and powerful ways for customization.

torch for optimization
Torch is not just for deep learning. Its L-BFGS optimizer, complete with Strong-Wolfe line search, is a powerful tool in unconstrained as well as constrained optimization.

sparklyr 1.6: weighted quantile summaries, power iteration clustering, spark_write_rds(), and more
The sparklyr 1.6 release introduces weighted quantile summaries, an R interface to power iteration clustering, spark_write_rds(), as well as a number of dplyr-related improvements.

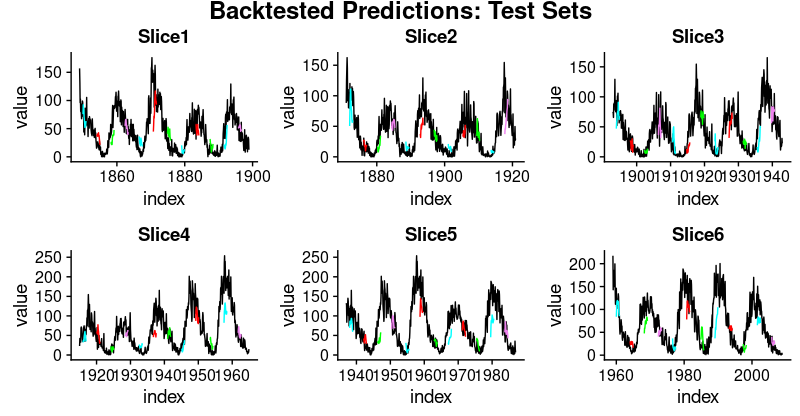
torch time series, final episode: Attention
We conclude our mini-series on time-series forecasting with torch by augmenting last time's sequence-to-sequence architecture with a technique both immensely popular in natural language processing and inspired by human (and animal) cognition: attention.

torch time series, take three: Sequence-to-sequence prediction
In our overview of techniques for time-series forecasting, we move on to sequence-to-sequence models. Architectures in this family are commonly used in natural language processing (NLP) tasks, such as machine translation. With NLP, however, significant pre-processing is required before proceeding to model definition and training. In staying with our familiar numerical series, we can fully concentrate on the concepts.

torch time series continued: A first go at multi-step prediction
We continue our exploration of time-series forecasting with torch, moving on to architectures designed for multi-step prediction. Here, we augment the "workhorse RNN" by a multi-layer perceptron (MLP) to extrapolate multiple timesteps into the future.

Introductory time-series forecasting with torch
This post is an introduction to time-series forecasting with torch. Central topics are data input, and practical usage of RNNs (GRUs/LSTMs). Upcoming posts will build on this, and introduce increasingly involved architectures.

First mlverse survey results – software, applications, and beyond
Last month, we conducted our first survey on mlverse software, covering topics ranging from area of application through software usage to user wishes and suggestions. In addition, the survey asked about thoughts on social impacts of AI/ML. This post presents the results, and tries to address some of the things that came up.

torch, tidymodels, and high-energy physics
Today we introduce tabnet, a torch implementation of "TabNet: Attentive Interpretable Tabular Learning" that is fully integrated with the tidymodels framework. Per se, already, tabnet was designed to require very little data pre-processing; thanks to tidymodels, hyperparameter tuning (so often cumbersome in deep learning) becomes convenient and even, fun!

Simple audio classification with torch
This article translates Daniel Falbel's post on "Simple Audio Classification" from TensorFlow/Keras to torch/torchaudio.

Forecasting El Niño-Southern Oscillation (ENSO)
El Niño-Southern Oscillation (ENSO) is an atmospheric phenomenon, located in the tropical Pacific, that greatly affects ecosystems as well as human well-being on a large portion of the globe. We use the convLSTM introduced in a prior post to predict the Niño 3.4 Index from spatially-ordered sequences of sea surface temperatures.

Convolutional LSTM for spatial forecasting
In forecasting spatially-determined phenomena (the weather, say, or the next frame in a movie), we want to model temporal evolution, ideally using recurrence relations. At the same time, we'd like to efficiently extract spatial features, something that is normally done with convolutional filters. Ideally then, we'd have at our disposal an architecture that is both recurrent and convolutional. In this post, we build a convolutional LSTM with torch.

torch 0.2.0 - Initial JIT support and many bug fixes
The torch 0.2.0 release includes many bug fixes and some nice new features like initial JIT support, multi-worker dataloaders, new optimizers and a new print method for nn_modules.

sparklyr 1.5: better dplyr interface, more sdf_* functions, and RDS-based serialization routines
Unlike all three previous sparklyr releases, the recent release of sparklyr 1.5 placed much more emphasis on enhancing existing sparklyr features rather than creating new ones. As a result, many valuable suggestions from sparklyr users were taken into account and were successfully addressed in a long list of bug fixes and improvements.
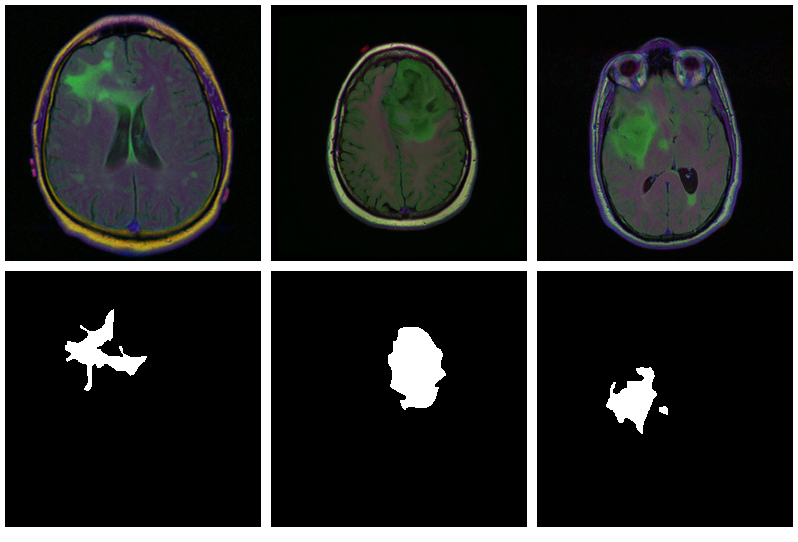
Brain image segmentation with torch
The need to segment images arises in various sciences and their applications, many of which are vital to human (and animal) life. In this introductory post, we train a U-Net to mark lesioned regions on MRI brain scans.

torch for tabular data
How not to die from poisonous mushrooms. Also: How to use torch for deep learning on tabular data, including a mix of categorical and numerical features.

Classifying images with torch
We learn about transfer learning, input pipelines, and learning rate schedulers, all while using torch to tell apart species of beautiful birds.

sparklyr.flint 0.2: ASOF Joins, OLS Regression, and additional summarizers
We are excited to announce a number of powerful, new functionalities and improvements which are now part of sparklyr.flint 0.2!

Optimizers in torch
Today, we wrap up our mini-series on torch basics, adding to our toolset two abstractions: loss functions and optimizers.

Using torch modules
In this third installment of our mini-series introducing torch basics, we replace hand-coded matrix operations by modules, considerably simplifying our toy network's code.

Introducing torch autograd
With torch, there is hardly ever a reason to code backpropagation from scratch. Its automatic differentiation feature, called autograd, keeps track of operations that need their gradients computed, as well as how to compute them. In this second post of a four-part series, we update our simple, hand-coded network to make use of autograd.

Getting familiar with torch tensors
In this first installment of a four-part miniseries, we present the main things you will want to know about torch tensors. As an illustrative example, we'll code a simple neural network from scratch.

sparklyr 1.4: Weighted Sampling, Tidyr Verbs, Robust Scaler, RAPIDS, and more
Sparklyr 1.4 is now available! This release comes with delightful new features such as weighted sampling and tidyr verbs support for Spark dataframes, robust scaler for standardizing data based on median and interquartile range, spark_connect interface for RAPIDS GPU acceleration plugin, as well as a number of dplyr-related improvements.

Please allow me to introduce myself: Torch for R
Today, we are excited to introduce torch, an R package that allows you to use PyTorch-like functionality natively from R. No Python installation is required: torch is built directly on top of libtorch, a C++ library that provides the tensor-computation and automatic-differentiation capabilities essential to building neural networks.

Introducing sparklyr.flint: A time-series extension for sparklyr
We are pleased to announce that sparklyr.flint, a sparklyr extension for analyzing time series at scale with Flint, is now available on CRAN. Flint is an open-source library for working with time-series in Apache Spark which supports aggregates and joins on time-series datasets.

An introduction to weather forecasting with deep learning
A few weeks ago, we showed how to forecast chaotic dynamical systems with deep learning, augmented by a custom constraint derived from domain-specific insight. Global weather is a chaotic system, but of much higher complexity than many tasks commonly addressed with machine and/or deep learning. In this post, we provide a practical introduction featuring a simple deep learning baseline for atmospheric forecasting. While far away from being competitive, it serves to illustrate how more sophisticated and compute-intensive models may approach that formidable task by means of methods situated on the "black-box end" of the continuum.

Training ImageNet with R
This post explores how to train large datasets with TensorFlow and R. Specifically, we present how to download and repartition ImageNet, followed by training ImageNet across multiple GPUs in distributed environments using TensorFlow and Apache Spark.

Deepfake detection challenge from R
A couple of months ago, Amazon, Facebook, Microsoft, and other contributors initiated a challenge consisting of telling apart real and AI-generated ("fake") videos. We show how to approach this challenge from R.

FNN-VAE for noisy time series forecasting
In the last part of this mini-series on forecasting with false nearest neighbors (FNN) loss, we replace the LSTM autoencoder from the previous post by a convolutional VAE, resulting in equivalent prediction performance but significantly lower training time. In addition, we find that FNN regularization is of great help when an underlying deterministic process is obscured by substantial noise.

State-of-the-art NLP models from R
Nowadays, Microsoft, Google, Facebook, and OpenAI are sharing lots of state-of-the-art models in the field of Natural Language Processing. However, fewer materials exist how to use these models from R. In this post, we will show how R users can access and benefit from these models as well.

Parallelized sampling using exponential variates
How can the seemingly iterative process of weighted sampling without replacement be transformed into something highly parallelizable? Turns out a well-known technique based on exponential variates accomplishes exactly that.

Time series prediction with FNN-LSTM
In a recent post, we showed how an LSTM autoencoder, regularized by false nearest neighbors (FNN) loss, can be used to reconstruct the attractor of a nonlinear, chaotic dynamical system. Here, we explore how that same technique assists in prediction. Matched up with a comparable, capacity-wise, "vanilla LSTM", FNN-LSTM improves performance on a set of very different, real-world datasets, especially for the initial steps in a multi-step forecast.

sparklyr 1.3: Higher-order Functions, Avro and Custom Serializers
Sparklyr 1.3 is now available, featuring exciting new functionalities such as integration of Spark higher-order functions and data import/export in Avro and in user-defined serialization formats.
Deep attractors: Where deep learning meets chaos
In nonlinear dynamics, when the state space is thought to be multidimensional but all we have for data is just a univariate time series, one may attempt to reconstruct the true space via delay coordinate embeddings. However, it is not clear a priori how to choose dimensionality and time lag of the reconstruction space. In this post, we show how to use an autoencoder architecture to circumvent the problem: Given just a scalar series of observations, the autoencoder directly learns to represent attractors of chaotic systems in adequate dimensionality.

Easy PixelCNN with tfprobability
PixelCNN is a deep learning architecture - or bundle of architectures - designed to generate highly realistic-looking images. To use it, no reverse-engineering of arXiv papers or search for reference implementations is required: TensorFlow Probability and its R wrapper, tfprobability, now include a PixelCNN distribution that can be used to train a straightforwardly-defined neural network in a parameterizable way.

Hacking deep learning: model inversion attack by example
Compared to other applications, deep learning models might not seem too likely as victims of privacy attacks. However, methods exist to determine whether an entity was used in the training set (an adversarial attack called member inference), and techniques subsumed under "model inversion" allow to reconstruct raw data input given just model output (and sometimes, context information). This post shows an end-to-end example of model inversion, and explores mitigation strategies using TensorFlow Privacy.

Towards privacy: Encrypted deep learning with Syft and Keras
Deep learning need not be irreconcilable with privacy protection. Federated learning enables on-device, distributed model training; encryption keeps model and gradient updates private; differential privacy prevents the training data from leaking. As of today, private and secure deep learning is an emerging technology. In this post, we introduce Syft, an open-source framework that integrates with PyTorch as well as TensorFlow. In an example use case, we obtain private predictions from a Keras model.

sparklyr 1.2: Foreach, Spark 3.0 and Databricks Connect
A new sparklyr release is now available. This sparklyr 1.2 release features new functionalities such as support for Databricks Connect, a Spark backend for the 'foreach' package, inter-op improvements for working with Spark 3.0 preview, as well as a number of bug fixes and improvements addressing user-visible pain points.

pins 0.4: Versioning
A new release of pins is available on CRAN today. This release adds support to time travel across dataset versions, which improves collaboration and protects your code from breaking when remote resources change unexpectedly.

A first look at federated learning with TensorFlow
The term "federated learning" was coined to describe a form of distributed model training where the data remains on client devices, i.e., is never shipped to the coordinating server. In this post, we introduce central concepts and run first experiments with TensorFlow Federated, using R.

Introducing: The RStudio AI Blog
This blog just got a new title: RStudio AI Blog. We explain why.

Infinite surprise - the iridescent personality of Kullback-Leibler divergence
Kullback-Leibler divergence is not just used to train variational autoencoders or Bayesian networks (and not just a hard-to-pronounce thing). It is a fundamental concept in information theory, put to use in a vast range of applications. Most interestingly, it's not always about constraint, regularization or compression. Quite on the contrary, sometimes it is about novelty, discovery and surprise.

NumPy-style broadcasting for R TensorFlow users
Broadcasting, as done by Python's scientific computing library NumPy, involves dynamically extending shapes so that arrays of different sizes may be passed to operations that expect conformity - such as adding or multiplying elementwise. In NumPy, the way broadcasting works is specified exactly; the same rules apply to TensorFlow operations. For anyone who finds herself, occasionally, consulting Python code, this post strives to explain.

First experiments with TensorFlow mixed-precision training
TensorFlow 2.1, released last week, allows for mixed-precision training, making use of the Tensor Cores available in the most recent NVidia GPUs. In this post, we report first experimental results and provide some background on what this is all about.

Differential Privacy with TensorFlow
Differential Privacy guarantees that results of a database query are basically independent of the presence in the data of a single individual. Applied to machine learning, we expect that no single training example influences the parameters of the trained model in a substantial way. This post introduces TensorFlow Privacy, a library built on top of TensorFlow, that can be used to train differentially private deep learning models from R.
tfhub: R interface to TensorFlow Hub
TensorFlow Hub is a library for the publication, discovery, and consumption of reusable parts of machine learning models. A module is a self-contained piece of a TensorFlow graph, along with its weights and assets, that can be reused across different tasks in a process known as transfer learning.
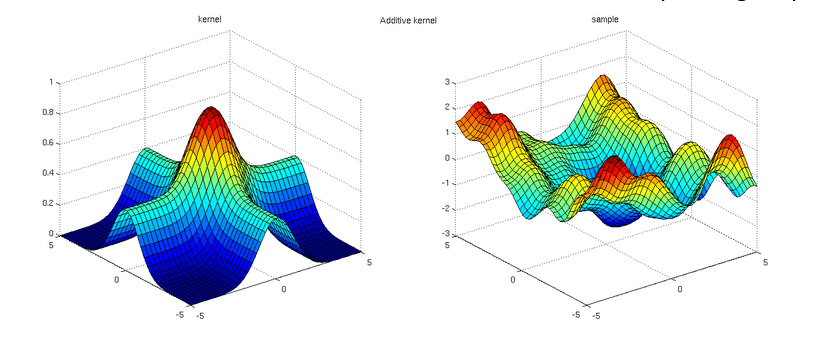
Gaussian Process Regression with tfprobability
Continuing our tour of applications of TensorFlow Probability (TFP), after Bayesian Neural Networks, Hamiltonian Monte Carlo and State Space Models, here we show an example of Gaussian Process Regression. In fact, what we see is a rather "normal" Keras network, defined and trained in pretty much the usual way, with TFP's Variational Gaussian Process layer pulling off all the magic.
Getting started with Keras from R - the 2020 edition
Looking for materials to get started with deep learning from R? This post presents useful tutorials, guides, and background documentation on the new TensorFlow for R website. Advanced users will find pointers to applications of new release 2.0 (or upcoming 2.1!) features alluded to in the recent TensorFlow 2.0 post.

Variational convnets with tfprobability
In a Bayesian neural network, layer weights are distributions, not tensors. Using tfprobability, the R wrapper to TensorFlow Probability, we can build regular Keras models that have probabilistic layers, and thus get uncertainty estimates "for free". In this post, we show how to define, train and obtain predictions from a probabilistic convolutional neural network.

tfprobability 0.8 on CRAN: Now how can you use it?
Part of the r-tensorflow ecosystem, tfprobability is an R wrapper to TensorFlow Probability, the Python probabilistic programming framework developed by Google. We take the occasion of tfprobability's acceptance on CRAN to give a high-level introduction, highlighting interesting use cases and applications.

Innocent unicorns considered harmful? How to experiment with GPT-2 from R
Is society ready to deal with challenges brought about by artificially-generated information - fake images, fake videos, fake text? While this post won't answer that question, it should help form an opinion on the threat exerted by fake text as of this writing, autumn 2019. We introduce gpt2, an R package that wraps OpenAI's public implementation of GPT-2, the language model that early this year surprised the NLP community with the unprecedented quality of its creations.

TensorFlow 2.0 is here - what changes for R users?
TensorFlow 2.0 was finally released last week. As R users we have two kinds of questions. First, will my keras code still run? And second, what is it that changes? In this post, we answer both and, then, give a tour of exciting new developments in the r-tensorflow ecosystem.
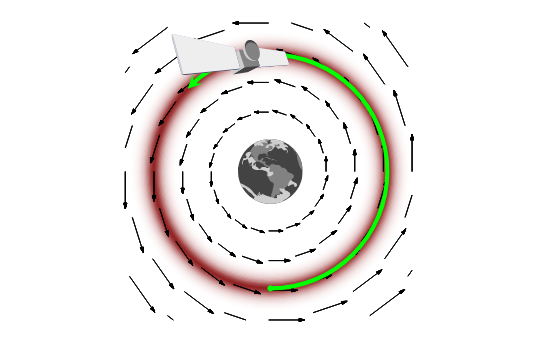
On leapfrogs, crashing satellites, and going nuts: A very first conceptual introduction to Hamiltonian Monte Carlo
TensorFlow Probability, and its R wrapper tfprobability, provide Markov Chain Monte Carlo (MCMC) methods that were used in a number of recent posts on this blog. These posts were directed to users already comfortable with the method, and terminology, per se, which readers mainly interested in deep learning won't necessarily be. Here we try to make up leeway, introducing Hamitonian Monte Carlo (HMC) as well as a few often-heard "buzzwords" accompanying it, always striving to keep in mind what it is all "for".

BERT from R
A deep learning model - BERT from Google AI Research - has yielded state-of-the-art results in a wide variety of Natural Language Processing (NLP) tasks. In this tutorial, we will show how to load and train the BERT model from R, using Keras.

So, how come we can use TensorFlow from R?
Have you ever wondered why you can call TensorFlow - mostly known as a Python framework - from R? If not - that's how it should be, as the R packages keras and tensorflow aim to make this process as transparent as possible to the user. But for them to be those helpful genies, someone else first has to tame the Python.
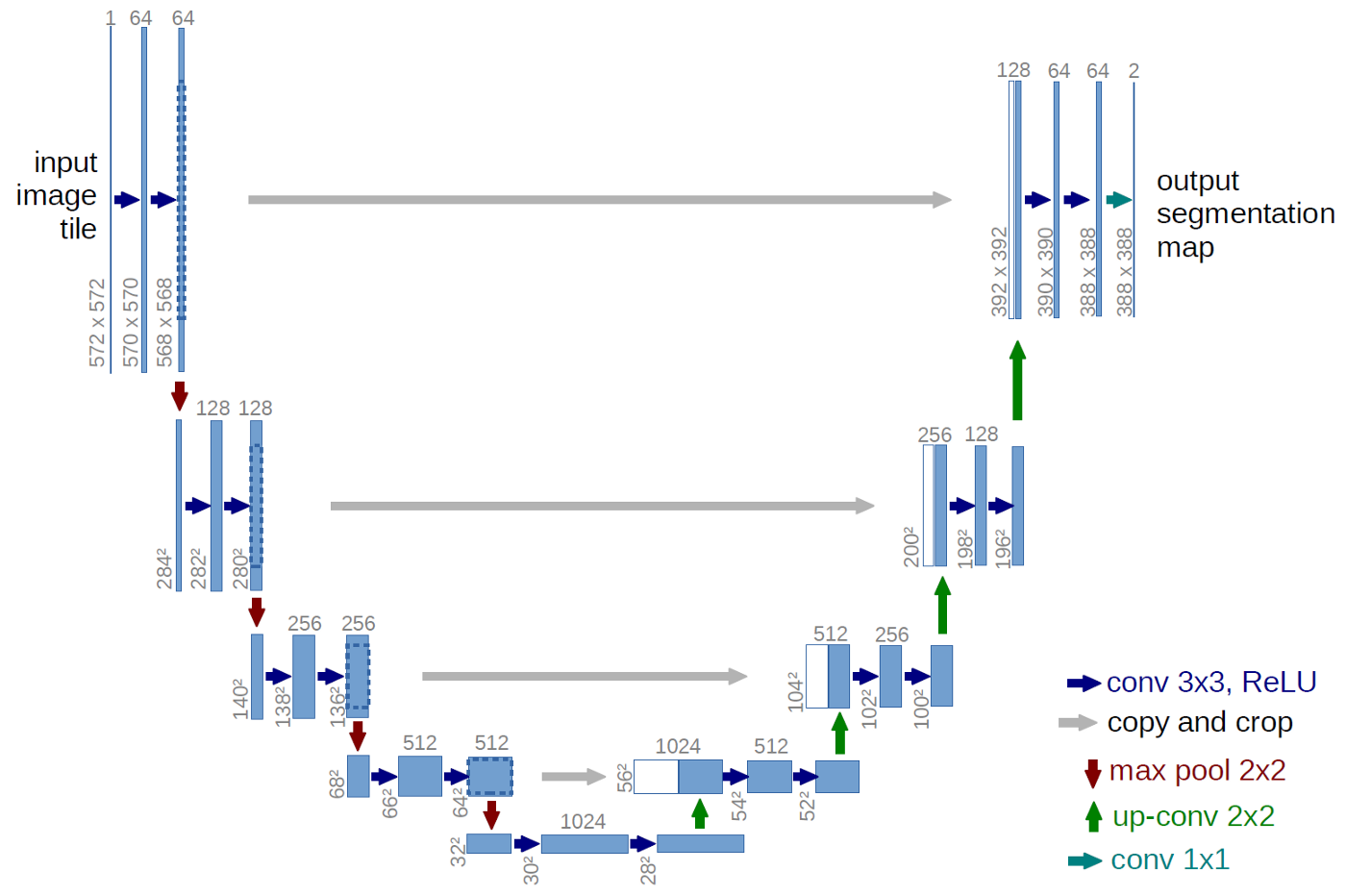
Image segmentation with U-Net
In image segmentation, every pixel of an image is assigned a class. Depending on the application, classes could be different cell types; or the task could be binary, as in "cancer cell yes or no?". Area of application notwithstanding, the established neural network architecture of choice is U-Net. In this post, we show how to preprocess data and train a U-Net model on the Kaggle Carvana image segmentation data.

Modeling censored data with tfprobability
In this post we use tfprobability, the R interface to TensorFlow Probability, to model censored data. Again, the exposition is inspired by the treatment of this topic in Richard McElreath's Statistical Rethinking. Instead of cute cats though, we model immaterial entities from the cold world of technology: This post explores durations of CRAN package checks, a dataset that comes with Max Kuhn's parsnip.
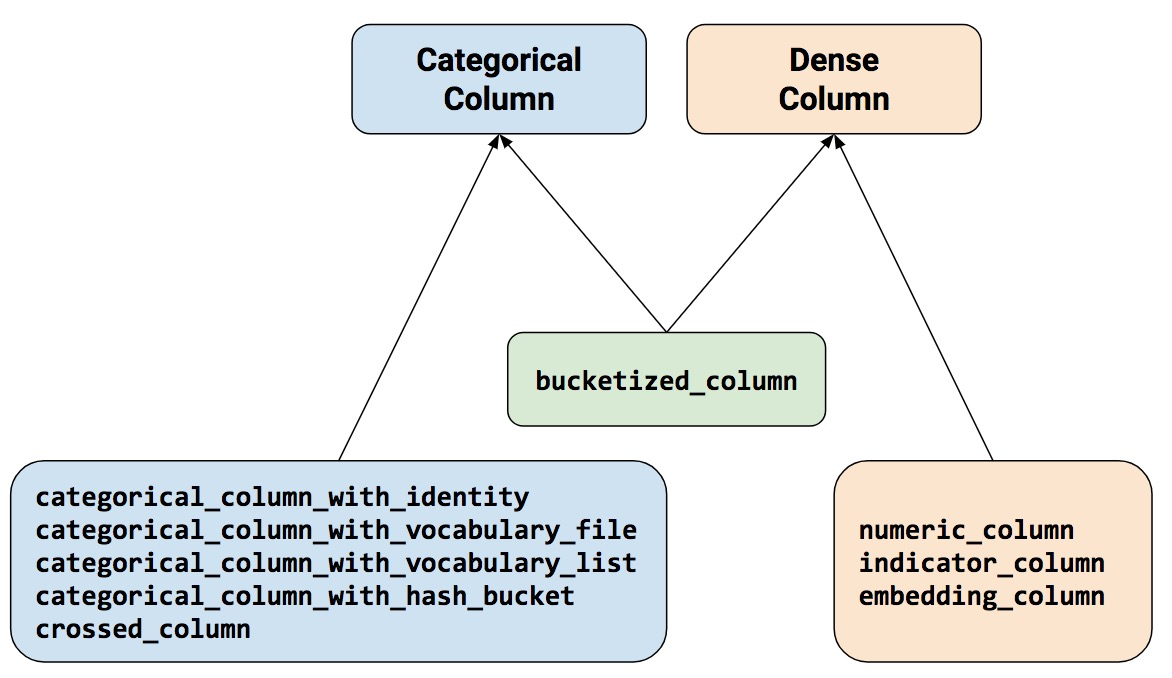
TensorFlow feature columns: Transforming your data recipes-style
TensorFlow feature columns provide useful functionality for preprocessing categorical data and chaining transformations, like bucketization or feature crossing. From R, we use them in popular "recipes" style, creating and subsequently refining a feature specification. In this post, we show how using feature specs frees cognitive resources and lets you focus on what you really want to accomplish. What's more, because of its elegance, feature-spec code reads nice and is fun to write as well.

Dynamic linear models with tfprobability
Previous posts featuring tfprobability - the R interface to TensorFlow Probability - have focused on enhancements to deep neural networks (e.g., introducing Bayesian uncertainty estimates) and fitting hierarchical models with Hamiltonian Monte Carlo. This time, we show how to fit time series using dynamic linear models (DLMs), yielding posterior predictive forecasts as well as the smoothed and filtered estimates from the Kálmán filter.
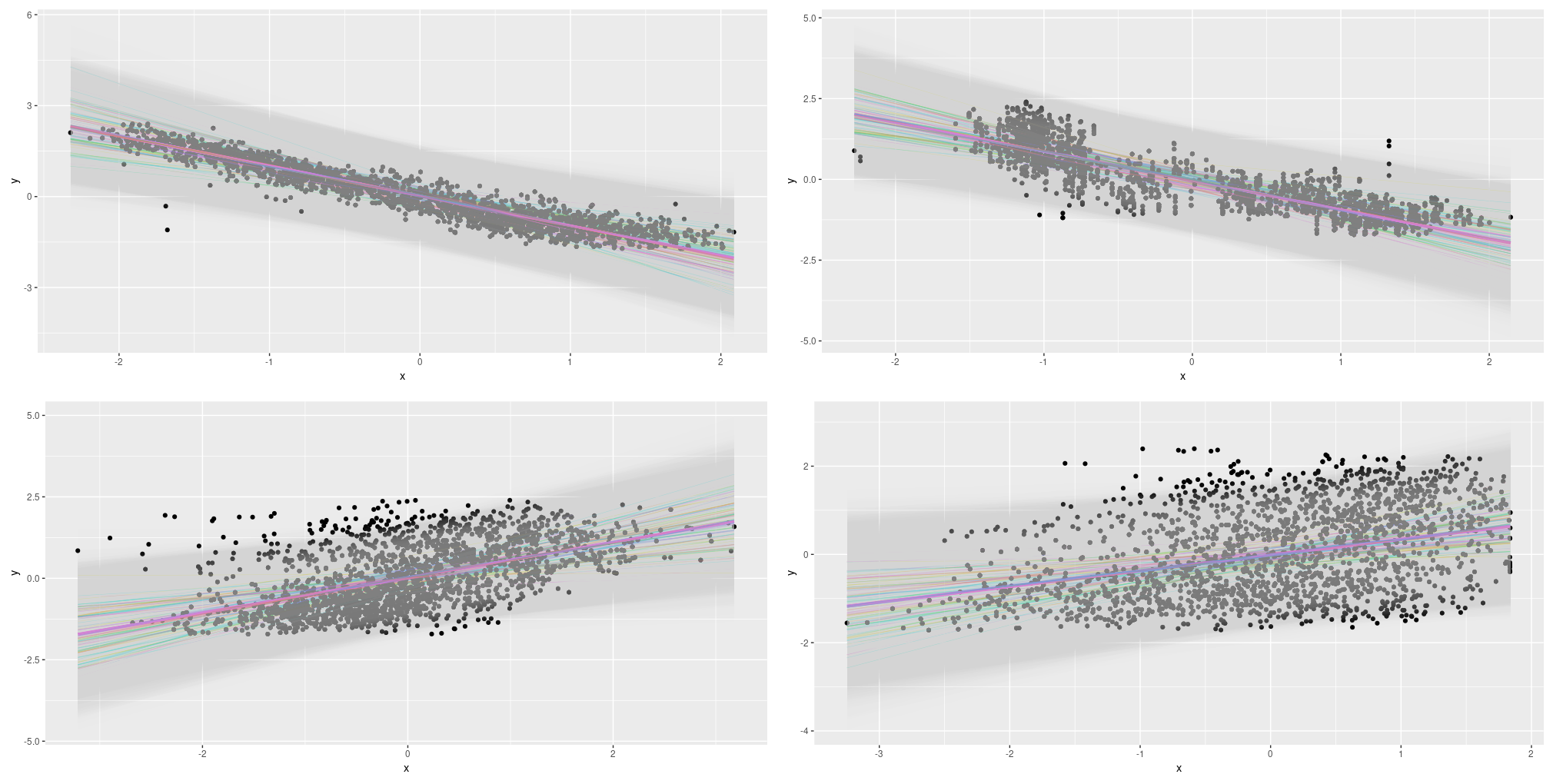
Adding uncertainty estimates to Keras models with tfprobability
As of today, there is no mainstream road to obtaining uncertainty estimates from neural networks. All that can be said is that, normally, approaches tend to be Bayesian in spirit, involving some way of putting a prior over model weights. This holds true as well for the method presented in this post: We show how to use tfprobability, the R interface to TensorFlow Probability, to add uncertainty estimates to a Keras model in an elegant and conceptually plausible way.
Hierarchical partial pooling, continued: Varying slopes models with TensorFlow Probability
This post builds on our recent introduction to multi-level modeling with tfprobability, the R wrapper to TensorFlow Probability. We show how to pool not just mean values ("intercepts"), but also relationships ("slopes"), thus enabling models to learn from data in an even broader way. Again, we use an example from Richard McElreath's "Statistical Rethinking"; the terminology as well as the way we present this topic are largely owed to this book.

Tadpoles on TensorFlow: Hierarchical partial pooling with tfprobability
This post is a first introduction to MCMC modeling with tfprobability, the R interface to TensorFlow Probability (TFP). Our example is a multi-level model describing tadpole mortality, which may be known to the reader from Richard McElreath's wonderful "Statistical Rethinking".

Experimenting with autoregressive flows in TensorFlow Probability
Continuing from the recent introduction to bijectors in TensorFlow Probability (TFP), this post brings autoregressivity to the table. Using TFP through the new R package tfprobability, we look at the implementation of masked autoregressive flows (MAF) and put them to use on two different datasets.

Auto-Keras: Tuning-free deep learning from R
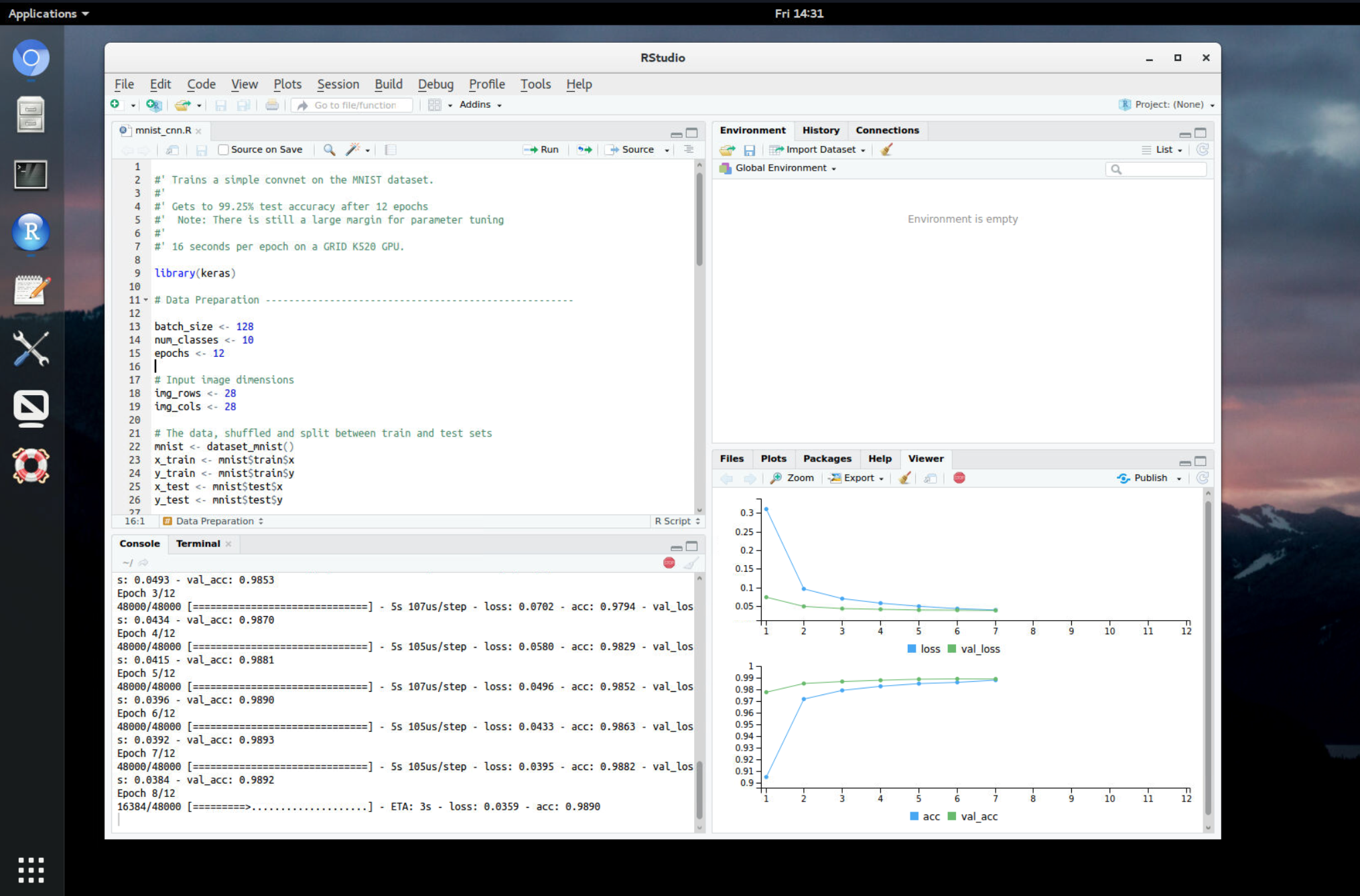
Sometimes in deep learning, architecture design and hyperparameter tuning pose substantial challenges. Using Auto-Keras, none of these is needed: We start a search procedure and extract the best-performing model. This post presents Auto-Keras in action on the well-known MNIST dataset.
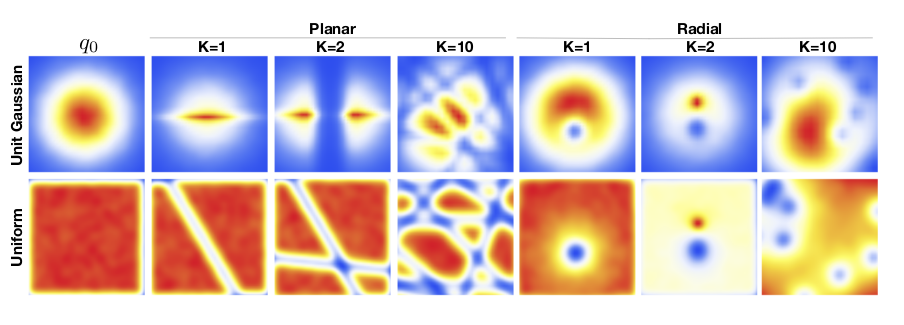
Getting into the flow: Bijectors in TensorFlow Probability
Normalizing flows are one of the lesser known, yet fascinating and successful architectures in unsupervised deep learning. In this post we provide a basic introduction to flows using tfprobability, an R wrapper to TensorFlow Probability. Upcoming posts will build on this, using more complex flows on more complex data.

Math, code, concepts: A third road to deep learning
Not everybody who wants to get into deep learning has a strong background in math or programming. This post elaborates on a concepts-driven, abstraction-based way to learn what it's all about.
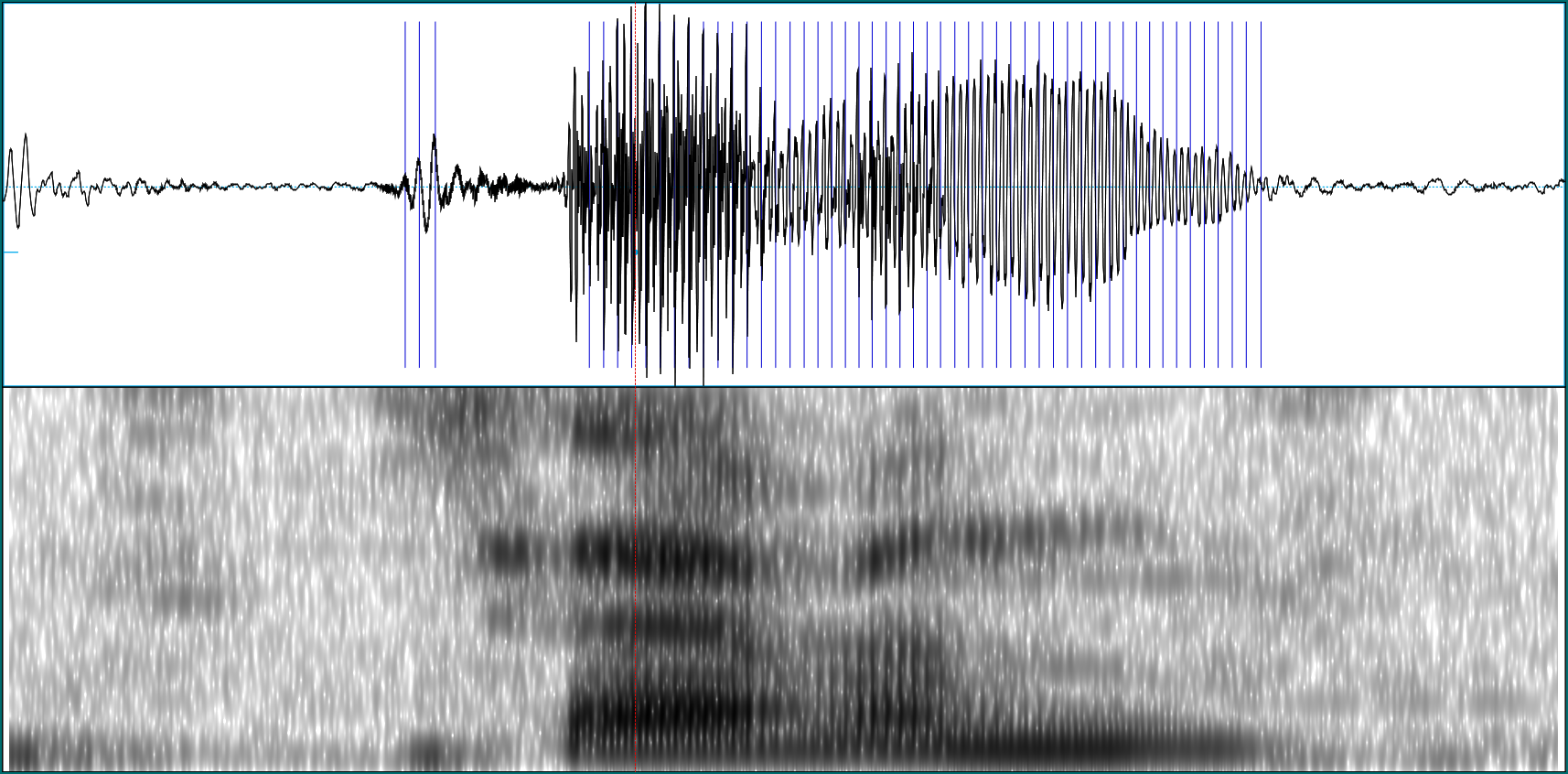
Audio classification with Keras: Looking closer at the non-deep learning parts
Sometimes, deep learning is seen - and welcomed - as a way to avoid laborious preprocessing of data. However, there are cases where preprocessing of sorts does not only help improve prediction, but constitutes a fascinating topic in itself. One such case is audio classification. In this post, we build on a previous post on this blog, this time focusing on explaining some of the non-deep learning background. We then link the concepts explained to updated for near-future releases TensorFlow code.
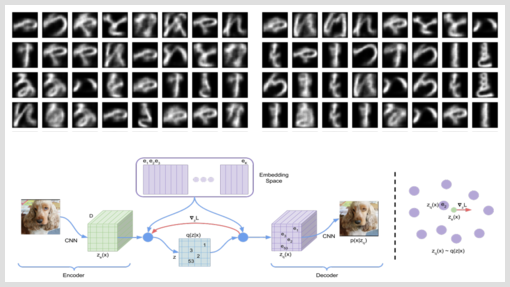
Discrete Representation Learning with VQ-VAE and TensorFlow Probability
Mostly when thinking of Variational Autoencoders (VAEs), we picture the prior as an isotropic Gaussian. But this is by no means a necessity. The Vector Quantised Variational Autoencoder (VQ-VAE) described in van den Oord et al's "Neural Discrete Representation Learning" features a discrete latent space that allows to learn impressively concise latent representations. In this post, we combine elements of Keras, TensorFlow, and TensorFlow Probability to see if we can generate convincing letters resembling those in Kuzushiji-MNIST.

Getting started with TensorFlow Probability from R
TensorFlow Probability offers a vast range of functionality ranging from distributions over probabilistic network layers to probabilistic inference. It works seamlessly with core TensorFlow and (TensorFlow) Keras. In this post, we provide a short introduction to the distributions layer and then, use it for sampling and calculating probabilities in a Variational Autoencoder.

Concepts in object detection
As shown in a previous post, naming and locating a single object in an image is a task that may be approached in a straightforward way. This is not the same with general object detection, though - naming and locating several objects at once, with no prior information about how many objects are supposed to be detected. In this post, we explain the steps involved in coding a basic single-shot object detector: Not unlike SSD (Single-shot Multibox Detector), but simplified and designed not for best performance, but comprehensibility.

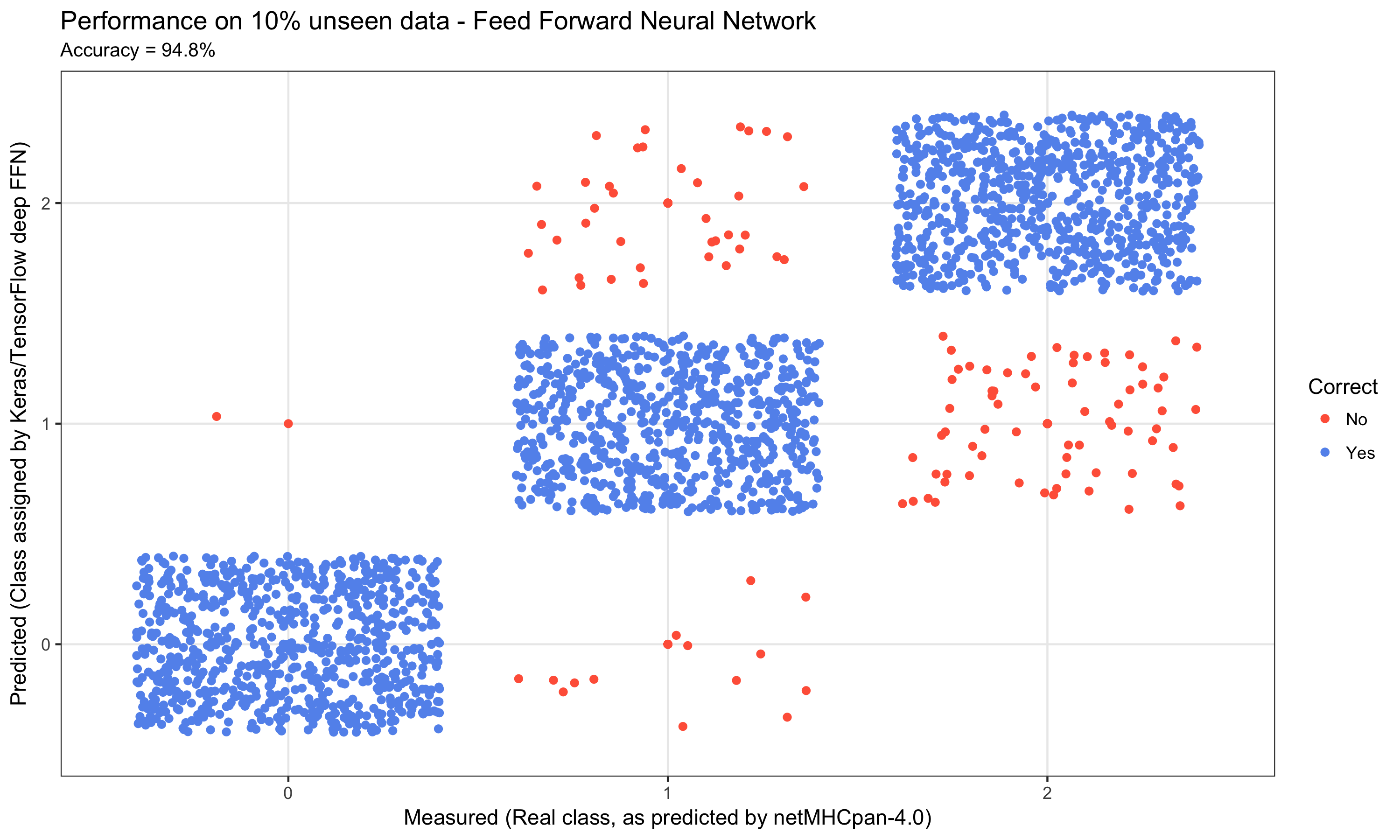
Entity embeddings for fun and profit
Embedding layers are not just useful when working with language data. As "entity embeddings", they've recently become famous for applications on tabular, small-scale data. In this post, we exemplify two possible use cases, also drawing attention to what not to expect.
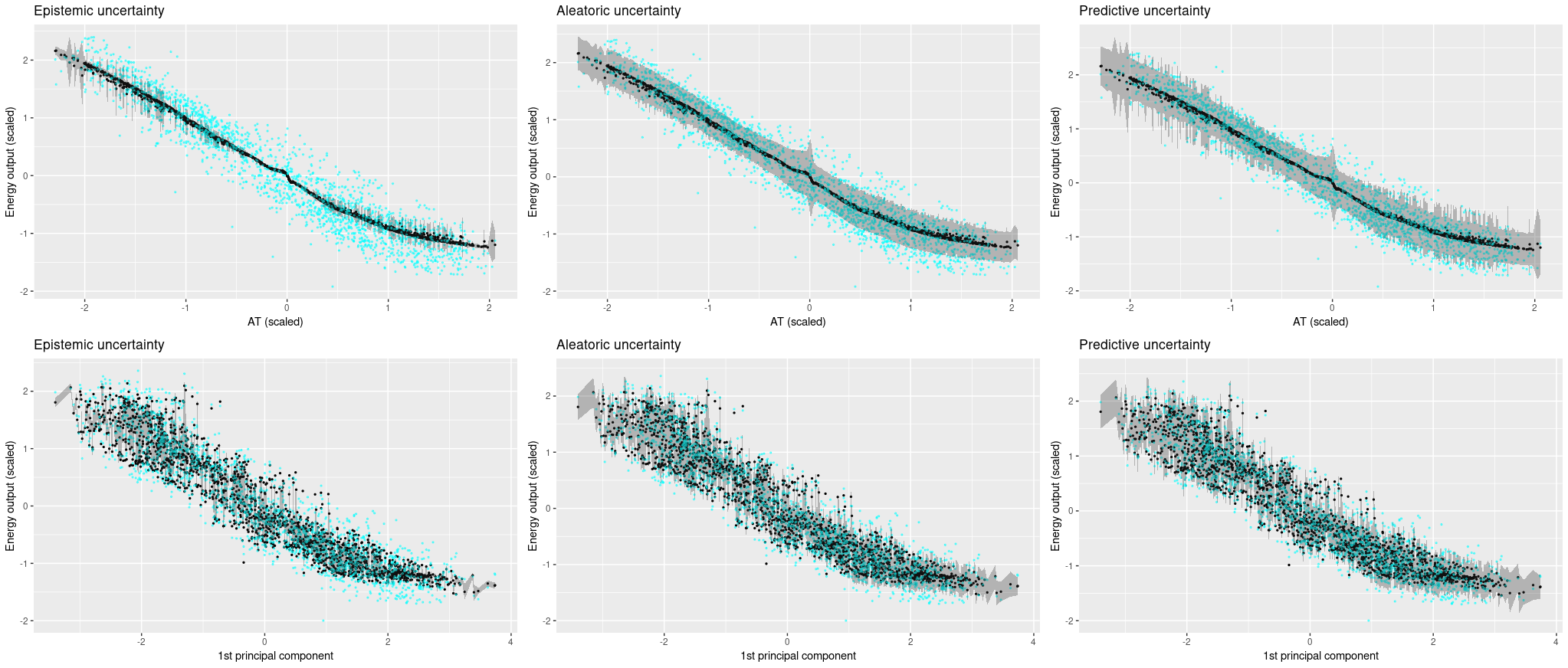
You sure? A Bayesian approach to obtaining uncertainty estimates from neural networks
In deep learning, there is no obvious way of obtaining uncertainty estimates. In 2016, Gal and Ghahramani proposed a method that is both theoretically grounded and practical: use dropout at test time. In this post, we introduce a refined version of this method (Gal et al. 2017) that has the network itself learn how uncertain it is.

Naming and locating objects in images
Object detection (the act of classifying and localizing multiple objects in a scene) is one of the more difficult, but very relevant in practice deep learning tasks. We'll build up to it in several posts. Here we start with the simpler tasks of naming and locating a single object.

Representation learning with MMD-VAE
Like GANs, variational autoencoders (VAEs) are often used to generate images. However, VAEs add an additional promise: namely, to model an underlying latent space. Here, we first look at a typical implementation that maximizes the evidence lower bound. Then, we compare it to one of the more recent competitors, MMD-VAE, from the Info-VAE (information maximizing VAE) family.

Winner takes all: A look at activations and cost functions
Why do we use the activations we use, and how do they relate to the cost functions they tend to co-appear with? In this post we provide a conceptual introduction.

More flexible models with TensorFlow eager execution and Keras
Advanced applications like generative adversarial networks, neural style transfer, and the attention mechanism ubiquitous in natural language processing used to be not-so-simple to implement with the Keras declarative coding paradigm. Now, with the advent of TensorFlow eager execution, things have changed. This post explores using eager execution with R.

Collaborative filtering with embeddings
Embeddings are not just for use in natural language processing. Here we apply embeddings to a common task in collaborative filtering - predicting user ratings - and on our way, strive for a better understanding of what an embedding layer really does.

Image-to-image translation with pix2pix
Conditional GANs (cGANs) may be used to generate one type of object based on another - e.g., a map based on a photo, or a color video based on black-and-white. Here, we show how to implement the pix2pix approach with Keras and eager execution.

Attention-based Image Captioning with Keras
Image captioning is a challenging task at intersection of vision and language. Here, we demonstrate using Keras and eager execution to incorporate an attention mechanism that allows the network to concentrate on image features relevant to the current state of text generation.

Neural style transfer with eager execution and Keras
Continuing our series on combining Keras with TensorFlow eager execution, we show how to implement neural style transfer in a straightforward way. Based on this easy-to-adapt example, you can easily perform style transfer on your own images.

Getting started with deep learning in R
Many fields are benefiting from the use of deep learning, and with the R keras, tensorflow and related packages, you can now easily do state of the art deep learning in R. In this post, we want to give some orientation as to how to best get started.

Generating images with Keras and TensorFlow eager execution
Generative adversarial networks (GANs) are a popular deep learning approach to generating new entities (often but not always images). We show how to code them using Keras and TensorFlow eager execution.

Attention-based Neural Machine Translation with Keras
As sequence to sequence prediction tasks get more involved, attention mechanisms have proven helpful. A prominent example is neural machine translation. Following a recent Google Colaboratory notebook, we show how to implement attention in R.
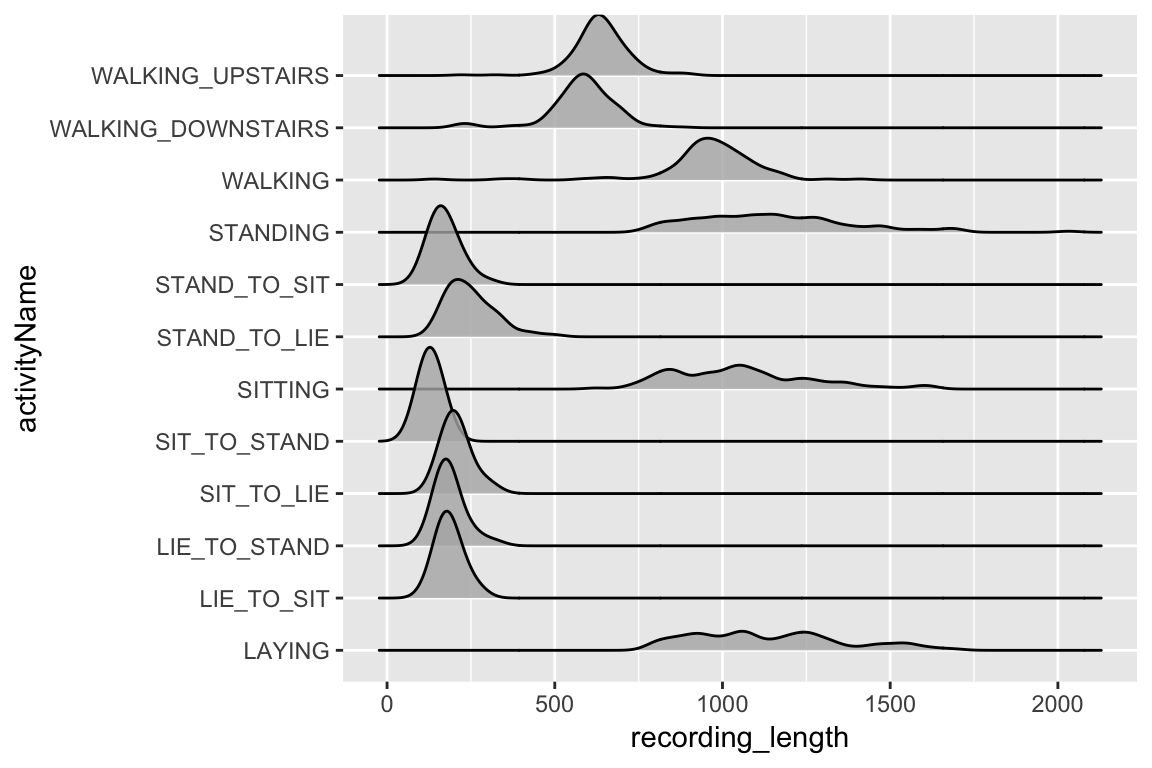
Classifying physical activity from smartphone data
Using Keras to train a convolutional neural network to classify physical activity. The dataset was built from the recordings of 30 subjects performing basic activities and postural transitions while carrying a waist-mounted smartphone with embedded inertial sensors.
Predicting Sunspot Frequency with Keras
In this post we will examine making time series predictions using the sunspots dataset that ships with base R. Sunspots are dark spots on the sun, associated with lower temperature. Our post will focus on both how to apply deep learning to time series forecasting, and how to properly apply cross validation in this domain.
Simple Audio Classification with Keras
In this tutorial we will build a deep learning model to classify words. We will use the Speech Commands dataset which consists of 65,000 one-second audio files of people saying 30 different words.
GPU Workstations in the Cloud with Paperspace
If you don't have local access to a modern NVIDIA GPU, your best bet is typically to run GPU intensive training jobs in the cloud. Paperspace is a cloud service that provides access to a fully preconfigured Ubuntu 16.04 desktop environment equipped with a GPU.

lime v0.4: The Kitten Picture Edition
A new major release of lime has landed on CRAN. lime is an R port of the Python library of the same name by Marco Ribeiro that allows the user to pry open black box machine learning models and explain their outcomes on a per-observation basis
Deep Learning for Cancer Immunotherapy
The aim of this post is to illustrate how deep learning is being applied in cancer immunotherapy (Immuno-oncology or Immunooncology) - a cancer treatment strategy, where the aim is to utilize the cancer patient's own immune system to fight the cancer.

Predicting Fraud with Autoencoders and Keras
In this post we will train an autoencoder to detect credit card fraud. We will also demonstrate how to train Keras models in the cloud using CloudML. The basis of our model will be the Kaggle Credit Card Fraud Detection dataset.
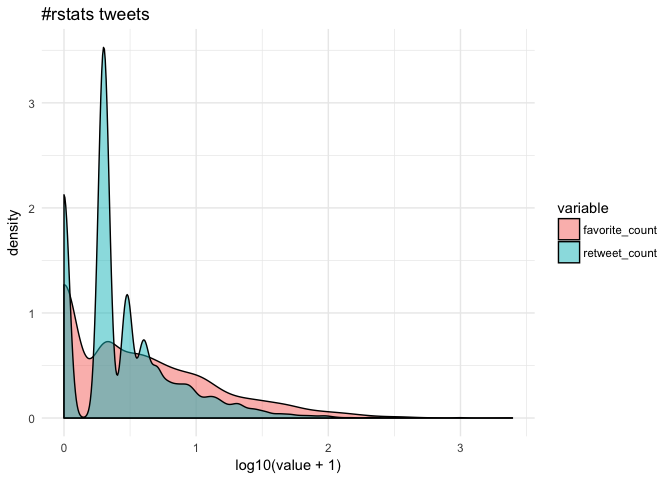
Analyzing rtweet Data with kerasformula
The kerasformula package offers a high-level interface for the R interface to Keras. It’s main interface is the kms function, a regression-style interface to keras_model_sequential that uses formulas and sparse matrices. We use kerasformula to predict how popular tweets will be based on how often the tweet was retweeted and favorited.
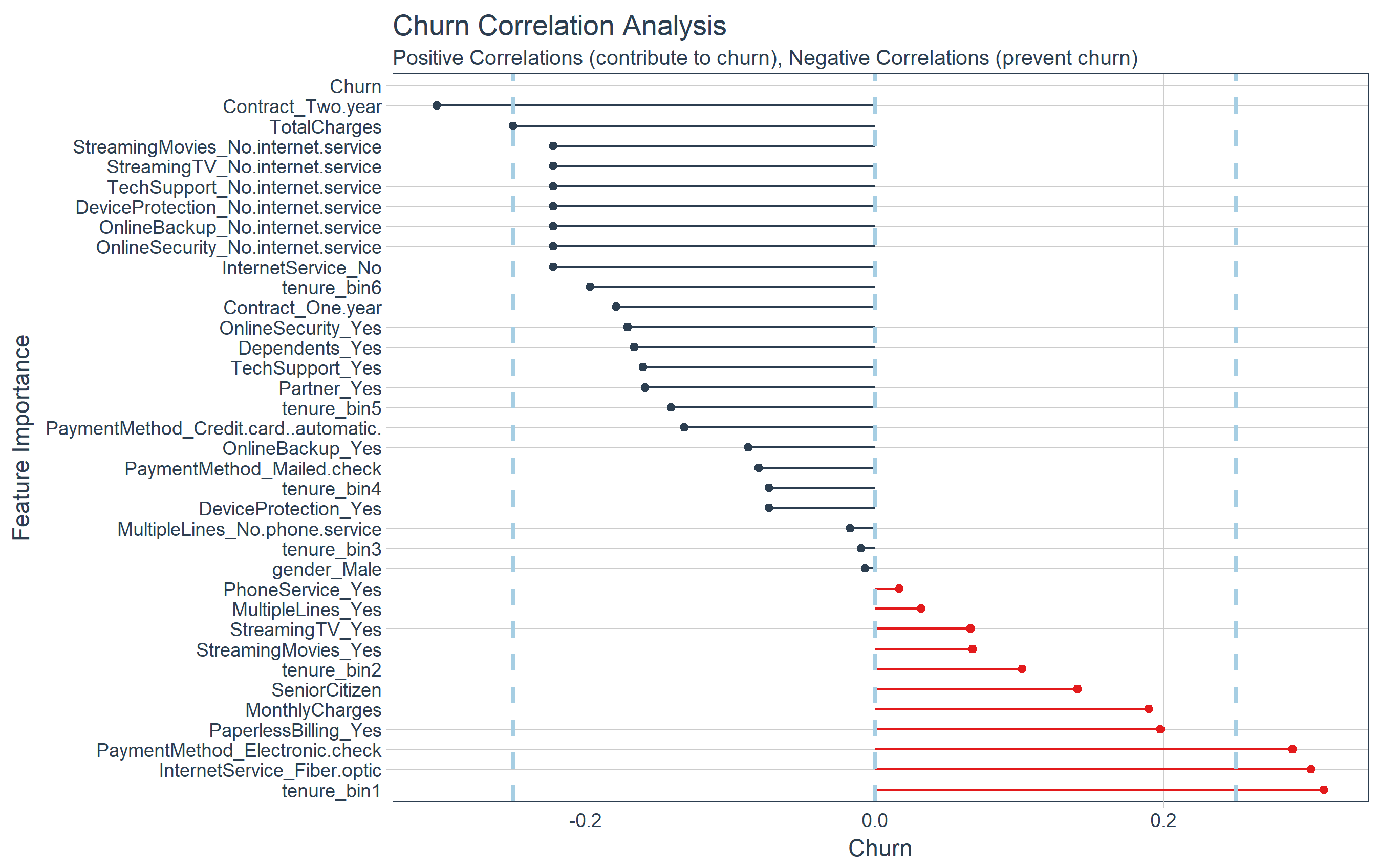
Deep Learning With Keras To Predict Customer Churn
Using Keras to predict customer churn based on the IBM Watson Telco Customer Churn dataset. We also demonstrate using the lime package to help explain which features drive individual model predictions. In addition, we use three new packages to assist with Machine Learning: recipes for preprocessing, rsample for sampling data and yardstick for model metrics.

R Interface to Google CloudML
We are excited to announce the availability of the cloudml package, which provides an R interface to Google Cloud Machine Learning Engine. CloudML provides a number of services including on-demand access to training on GPUs and hyperparameter tuning to optimize key attributes of model architectures.

Classifying Duplicate Questions from Quora with Keras
In this post we will use Keras to classify duplicated questions from Quora. Our implementation is inspired by the Siamese Recurrent Architecture, with modifications to the similarity measure and the embedding layers (the original paper uses pre-trained word vectors)

Word Embeddings with Keras
Word embedding is a method used to map words of a vocabulary to dense vectors of real numbers where semantically similar words are mapped to nearby points. In this example we'll use Keras to generate word embeddings for the Amazon Fine Foods Reviews dataset.
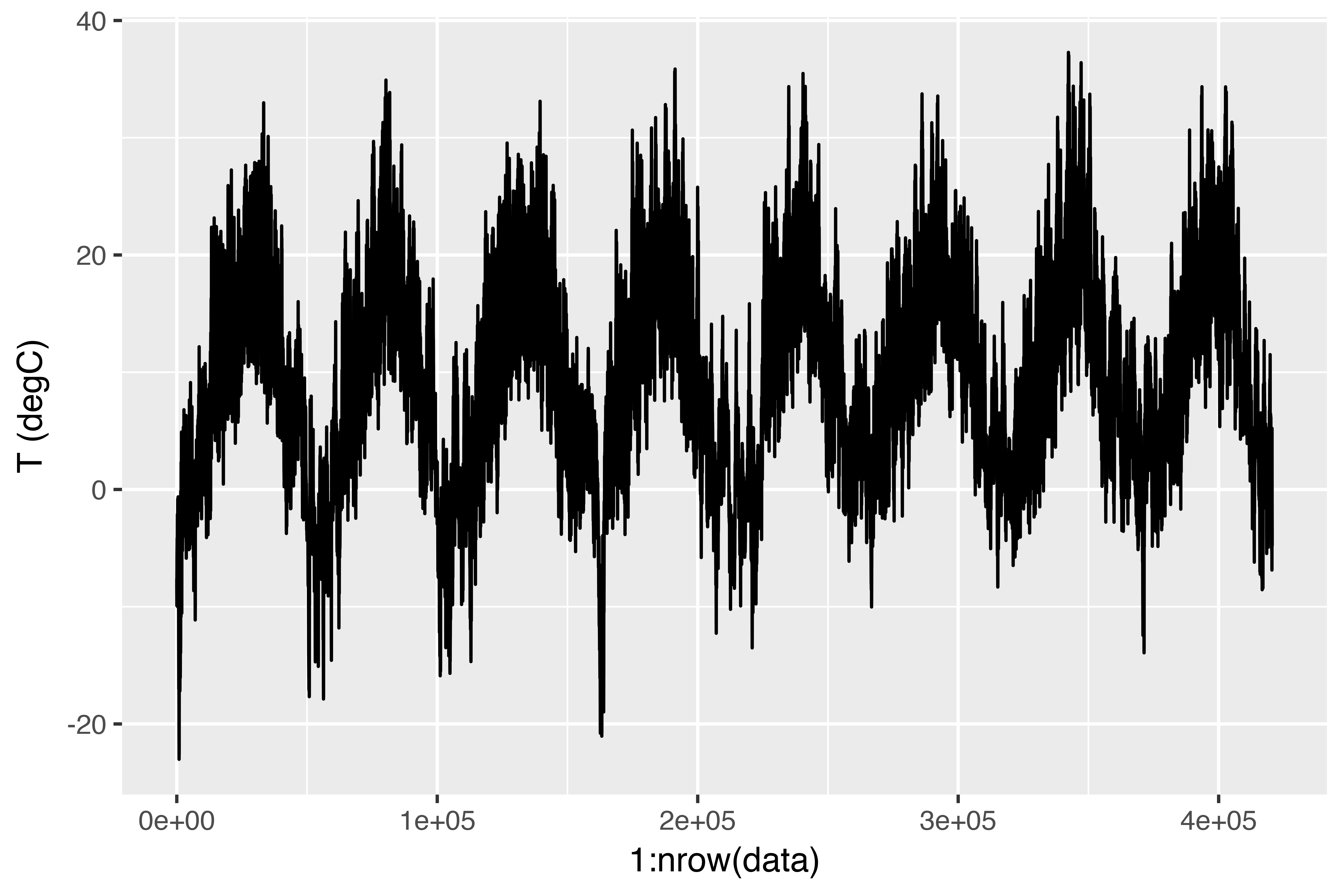
Time Series Forecasting with Recurrent Neural Networks
In this post, we'll review three advanced techniques for improving the performance and generalization power of recurrent neural networks. We'll demonstrate all three concepts on a temperature-forecasting problem, where you have access to a time series of data points coming from sensors installed on the roof of a building.
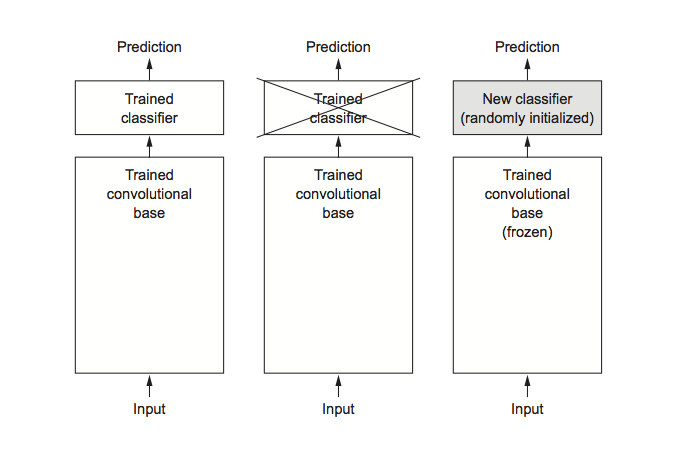
Image Classification on Small Datasets with Keras
Having to train an image-classification model using very little data is a common situation, in this article we review three techniques for tackling this problem including feature extraction and fine tuning from a pretrained network.
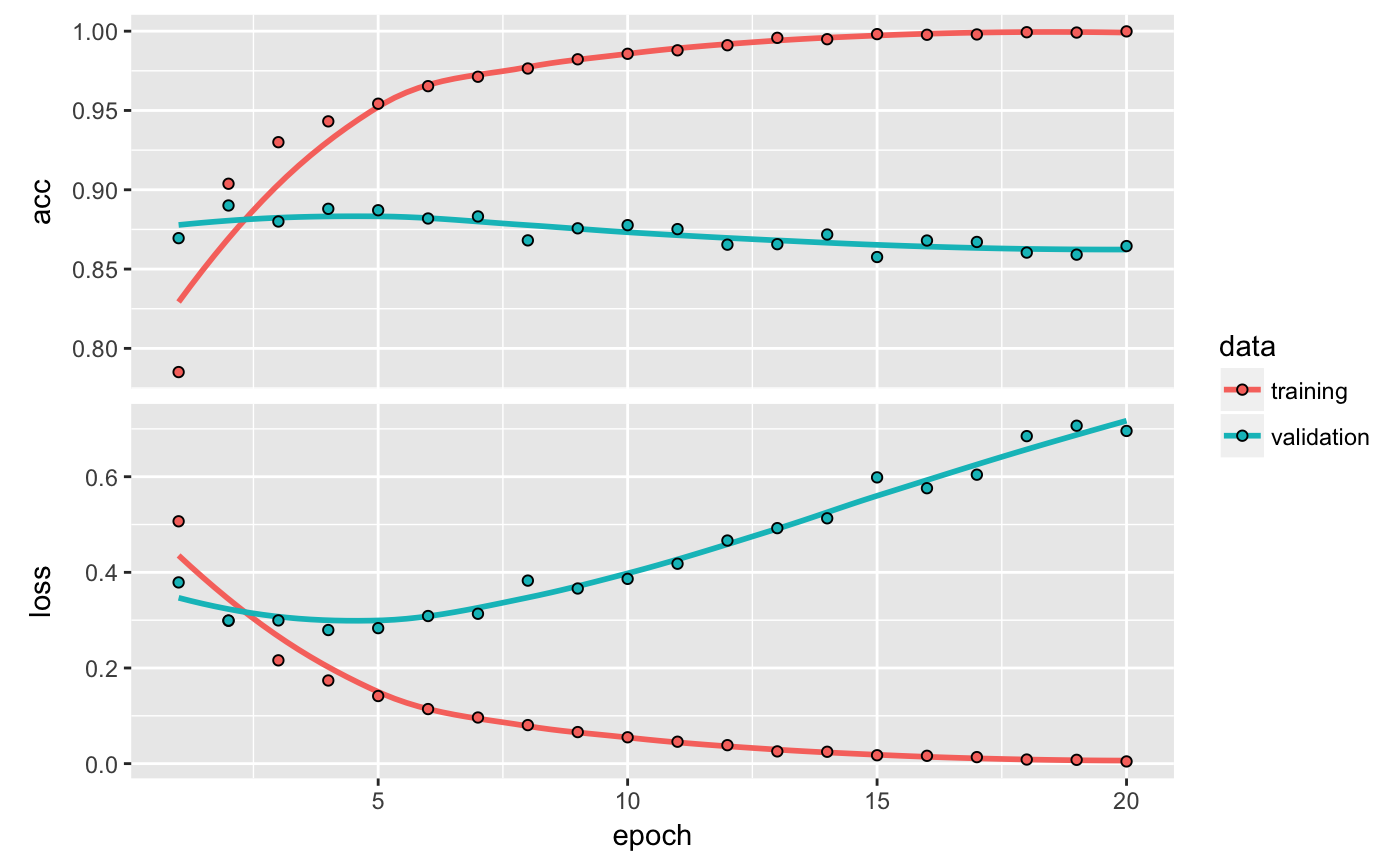
Deep Learning for Text Classification with Keras
Two-class classification, or binary classification, may be the most widely applied kind of machine-learning problem. In this excerpt from the book Deep Learning with R, you'll learn to classify movie reviews as positive or negative, based on the text content of the reviews.

tfruns: Tools for TensorFlow Training Runs
The tfruns package provides a suite of tools for tracking, visualizing, and managing TensorFlow training runs and experiments from R.

Keras for R
We are excited to announce that the keras package is now available on CRAN. The package provides an R interface to Keras, a high-level neural networks API developed with a focus on enabling fast experimentation.

TensorFlow Estimators
The tfestimators package is an R interface to TensorFlow Estimators, a high-level API that provides implementations of many different model types including linear models and deep neural networks.
TensorFlow v1.3 Released
The final release of TensorFlow v1.3 is now available. This release marks the initial availability of several canned estimators including DNNClassifier and DNNRegressor.